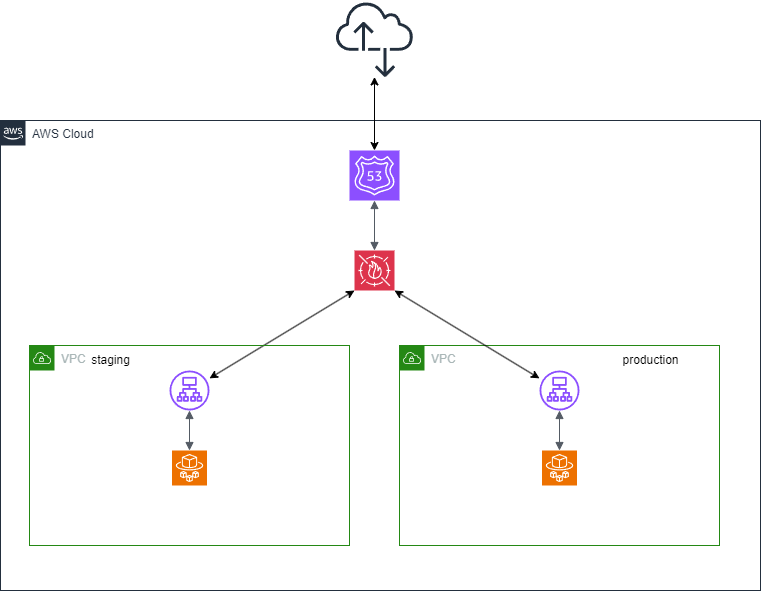
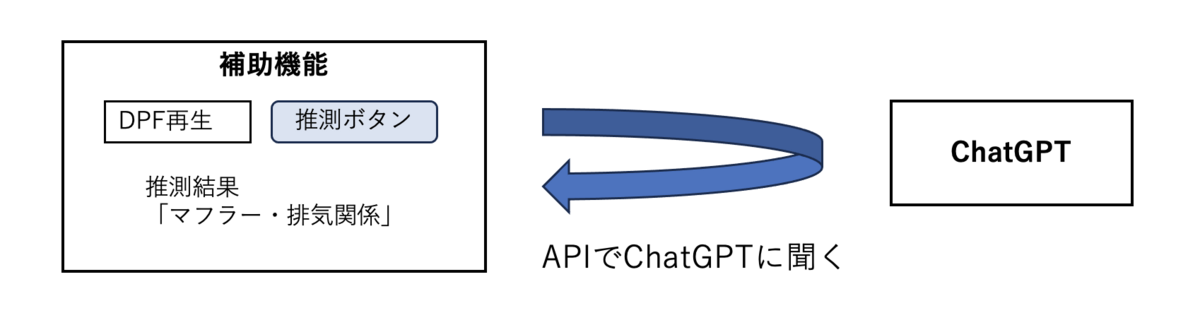
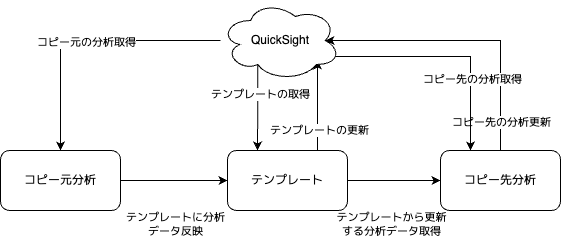
お世話になっております。
株式会社Azoopでトラッカーズマネージャーおよびトラッカーズジョブの開発を担当している中山です。
先日、11月28日(水)にベルサール汐留で開催されたFindy様主催の「開発生産性の未来:世界と日本の最前線事例から培うFour Keys向上〜ハイブリッドカンファレンス〜」にオフラインで参加しました。
備忘録として、全体通しての感想と、いくつかのセッションについての感想をまとめていきます!
全体通しての感想
各セッションで以下のような話を聞く機会が多かったです。
- Four Keysやプルリクエスト作成数などをモニタリングすることで、開発チーム内でそれらの数値の改善を促す事ができ、結果それらの数値は改善することが出来た
- 開発チーム内の生産性をどのようにしてその先の開発生産性*1のモニタリングや改善に繋げていくか、模索中である
弊社はまず開発チーム内の生産性モニタリングから始める必要がありますが、実際にモニタリングを開始し、チームが良い状態に向かっているという事例を複数聞くことができ、開発生産性に取り組むモチベーションを高めることができました。また、取り組む過程で直面する可能性のあるいくつかの課題についても聞くことができ、大変有意義でした。

「日本における開発生産性の現在地」
ファインディ株式会社様のオープニングセッションになります。
セッションは、「開発生産性」というテーマが昨年より注目されていることについて触れる形で始まりました。
Findy Team+の導入チーム数が約12,000に達していると仰っていて、数字にこの分野への関心の高さが反映されていると思いました。
また、他のセッションでも度々話題になった生成AIの台頭が、開発生産性への注目に影響しているかなと個人的に感じました。
巷では「プログラマーは不要になる」との声も聞かれますが、それが言い過ぎであっても、開発チームの存在意義や活動を定量的な数字として、示すことができる状態になっている必要はあるなと感じます。
さらに、転職希望者が転職先を選ぶ際、「開発生産性への取り組み」を重視することが多いようです。
「開発生産性への取り組み」は個人だけでなく、チームや会社全体で取り組むべき課題です。モチベーションが高い人材を引き寄せるためにも、開発生産性への取り組みの実施、それを社外に発信することが重要だと感じました。
「開発生産性向上に向けた定量的なチーム目標設定のメリット」
株式会社モリサワ様とGO株式会社様のセッションになります。
モリサワ様の社内には、1日1人1プルリクエストを目標とするチームがあるそうで、すごいなと思いました。
プルリクエスト数を目標にすることで、プルリクエストに対する「ハック」が起きるのではという懸念の声に対しては、プルリクエストは課題ベースで作成するという前提に立った上で、「ハックはご自由に」「いくらでもプルリクエストは細かくしてください」「まずは数値を上げましょう」と伝えているそうです。
「まずは数値を上げましょう」というアプローチは、個人的にとても好きです。
自分たちに合った開発生産性を事前に定義することが可能な場合はそれに越したことはありませんが、多くのそうでない場合は、定義作成に多くの時間を費やすよりも、実際に数値を追いかけて見ることが良いと思っています。
そのプロセスの中で得られる知見をもとに、自分たちに合った開発生産性の定義を模索していく方が効果的だと思うからです。
チームの運営においても、アジャイルな価値観を取り入れたチーム作りを目指すべきだと、個人的には感じています。
定量的なチーム目標設定のメリットとしては
- 目標を設定し、数値をモニタリングすることで、自律的な反省と改善を促す効果があった
- 数値の設定がチーム全体に「行動しなければ」という意識を生み出した
と両社似たような見解を示していました。
「アジャイルな価値観への変革〜大手開発組織によるDX推進〜」
株式会社セゾン情報システムズ様とKINTOテクノロジーズ株式会社様のセッションになります。
セッションの本筋ではありませんが、セゾン情報システムズ様が自社の営業部に開発部のファンを作るという話が印象的でした。
「あの開発部が作った製品だから、自信を持って販売できる」と営業部に思ってもらうことが狙いだそうです。
今回の登壇も、社外でのプレゼンスを高め、営業部にファンを作る取り組みの一環として行っているそうです。
社員に自社製品のファンになってもらうという話はよく聞きますが、営業部の方に開発部のファンになってもらうというのは自分になかった視点でした。
この視点を踏まえると、「開発チームが社外に発信していること」を社内に共有することの重要性を感じます。
おまけ

各企業様からのノベルティです。
ANKERの充電器は、Findy様のブースにあったガチャガチャで当たりました!
ありがとうございます🙇
最後に
弊社の開発チームは現在15名となりましたが、引き続き採用活動を行っています。
次のような方を随時募集しています!
- Azoopの「開発生産性」向上に共に取り組んでくださる方
- カンファレンスへの参加を通じて、そこで得た知見をチームメンバーと共有してくださる方
- 開発チームの文化づくりが好きな方
選考プロセスへの進行なしでカジュアル面談を行うことも可能ですので、お気軽にお問い合わせください。
*1:開発生産性について議論する前に知っておきたいことで言及されているレベル2, 3の開発生産性やチームの目標が「とにかくたくさん開発する」はいけない“アウトプット”ではなく“アウトカム”を重視する体制作りで言及されているアウトカム